One of Alphaus’ data processing pipelines ingests around 10TB of client financial data per day. The processing engine is running on GKE with around 80-100 (depending on what week of the month) pods sharing the total workload. Each pod has around 10GB of memory and 30GB of attached storage. The consistency of this load allowed us to purchase enough Committed Use Discounts (CUDs) for the underlying VMs to save on compute costs.
These pod resource limits are usually enough 80% of the time. However, since late last year, some of the accounts have datasets that are way, way beyond these limits causing persistent OOMKilled events.
Our first stop-gap solution was to increase the memory limit. The trouble was, even with 20GB+ of memory wasn’t really enough for some of the input datasets. And on top of this, GKE’s cluster autoscaler also started increasing the VM sizes to those which we don’t have CUDs for. Suffice it to say, it increased our monthly cloud spend to about +20% while delaying the overall processing time due to pods crashing (and restarting).
We tried other solutions. One was using local files which required increasing the size of the attached storage. While cost-effective, the performance drop was significant mainly because most of the datasets that were well within the memory limit were now moved to disk as well. We also tried using the database we are currently using which turned out to be worse in terms of perfomance and costs. We also tried to use our cache layer (named Jupiter) which was very performant but prohibitively expensive.
Enter Spill-over Store (SoS), our current solution. Inspired by Apache Ignite’s design, the idea is to stitch together the already available memory and storage across the running pods, providing an ad-hoc, on-demand storage for really big datasets.
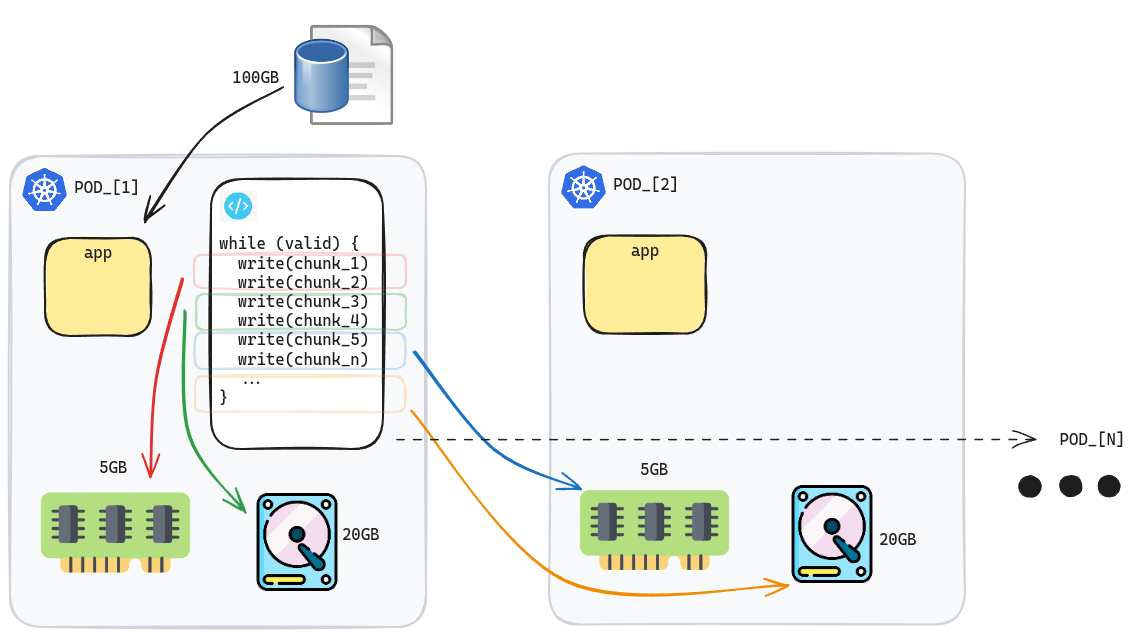
From the image above, the pod that is assigned to load a huge dataset will exhaust its local memory first, then “spill over” to its local disk, then another pod’s memory (using gRPC streaming), then disk, and so on. Thus, our example 100GB dataset will utilize around 4 pods in total within the cluster.
This solution allowed us to actually revert back to our original pod resource limits. Both disk and network performance are acceptable (we don’t use GCP’s Tier 1 network) and still within our SLA as the solution only applies to about 20% of the ingestion pipeline. The majority still uses local in-memory processing.
As Alphaus grows (and therefore ingests more and more data) and serve more clients, maybe we will eventually end up using Apache Ignite or some other off-the-shelf distributed solutions, but as of now, SoS works. With that said, if you have a cost-effective (and better) product/solution in mind, please feel free to contact us. We’d love to talk.
Finally, you can find SoS’s implementation here (if you’re interested).